Quite often we have several ways to perform a task. Sometimes we choose based on personal taste or affinity, others there is a context that enforces certain rules that limit our safe choices.
When working with software timers, I usually choose to use an old scheme based on multiple independent timers that has found its way through the assembly languages of many different micros and has finally landed in C. Sometimes, due to 32-bits being available, I may choose to simply check the value of a counter. In both cases, each timer and the counter are decremented and incremented (respectively) in an interrupt handler.
This requires that (in C) we declare this variable volatile so the compiler knows that this variable might change at any time without the compiler taking action in the surrounding code. Otherwise, loops waiting on this variable will be optimized out.
extern volatile uint32_t tickcounter;On the other hand, and due to the same reason, the access to this variable must be atomic, that is, it has to occur in a single processor instruction (or a non-interruptible sequence of them). Otherwise, the processor might accept an interrupt request in the middle of the instruction sequence that is reading the individual bytes forming this variable, and if this interrupt modifies this variable we would end up with an incorrect value. This happens, for example, if we use 32-bit counters/timers on most 8-bit micros; more info on this subject in another post.
Once we solve this issues, then there is the problem of counter length, the number of bits defining integer word size for our timers.
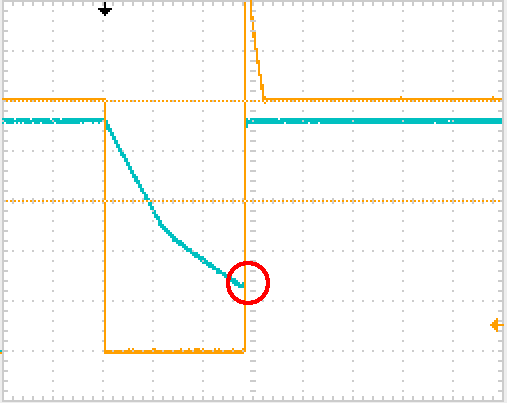
My timer scheme above is quite simple: each timer is decremented if it has a non-zero value, so to use one of this I simply write a value and then poll until I get a zero. There is obviously a jitter as there is a time gap from the moment I write the timer till it’s decremented by the interrupt handler, and another one since the timer reaches zero and the application reads the value.
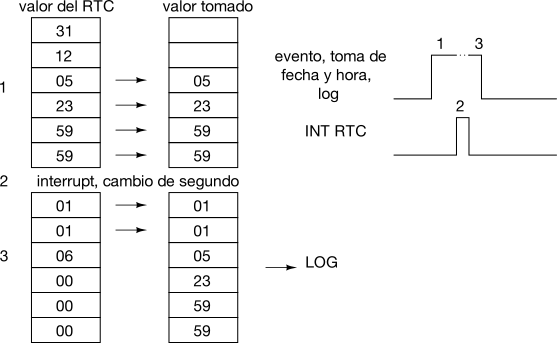
However, reading a counter, on the other hand, poses some issues; and their solutions were the inspiration to write this post. Because of atomicity, we might end up being forced to use a small variable, a short length counter that will overflow in a short time.
What happens when this counter overflows ? Well, maybe nothing happens, if we take precautionary measures.
Everything will work as a charm and all tests will pass as long as the counter doesn’t overflow between readings, that is, counter length is enough for the application lifetime. For example, a 32-bit seconds counter takes 136 years to overflow. However a 16-bit milliseconds counter overflows every minute and fraction (65536 milliseconds).
If the time between counter readings is larger, there is the possibility that the counter may overflow more than once between checks. In this situation, we must use an auxiliary resource, as the counter alone can’t do it.
If, however, we can be sure that the counter will overflow at most once between checks, we just need to write proper code in order for our comparison to survive this overflow. Otherwise, as we’ve already said, everything will work fine most of the time, but “sometimes” (every time there is a counter overflow) we’ll get a glitch.
For the sake of this analysis, let’s consider the following scheme, we are using uppercase names in violation of some coding styles but we do it for counter highlight’s sake:
extern volatile uint32_t MS_TIMER;
uint32_t interval = 5000; // milliseconds
uint32_t last_time;The following code snippets work fine, as the difference survives counter overflow and can be correctly compared to our desired value:
last_time = MS_TIMER;
if(MS_TIMER - last_time > interval)
printf("Timer expired\n");
if(MS_TIMER - interval > last_time)
printf("Timer expired\n");On the other hand, this does not work properly
uint32_t deadline;
/* I must not do this
deadline = MS_TIMER + interval;
if(MS_TIMER > deadline)
printf("Timer expired\n");
*/If, let’s say, MS_TIMER is 0xF8000000 and interval is 0x10000000, then deadline will be 0x08000000 and MS_TIMER is clearly larger than deadline from the beginning, this causes the timer to expire immediately (and that is not what we want…).
A workaround is to use signed integers, and this works with time intervals up to MAXINT32 units:
int32_t deadline;
int32_t interval = 5000; // milliseconds
deadline = MS_TIMER + interval;
if((int32_t)(MS_TIMER - deadline) > 0)
printf("Timer expired\n");To dive into more creative ways might result in timers that never expire when the counter is higher than MAXINT32, as this is seen as a negative number and so smaller than any desired time (that is a positive number); but do work when our device is started or reset. These can be considered as errors when choosing counter length (including sign).
As we’ve seen, some problems show themselves when referring to a time that is MAXINT32 time units after the system starts. This is usually 2^31, and this, for a milliseconds counter, is around 25 days; and for a seconds counter about 68 years. There can be several errors lurking deeply inside some Linux (and other Un*x-like) systems that will surface once they need to make reference to a time after year 2038 (the seconds counter starts at the beginning of year 1970).
If, on the other hand, we use 16- or 8-bit schemas…
In these examples we used ‘greater than’ in comparisons; this guarantees that the time interval will be longer than requested. If, for example, we set it right now and ask for a one second interval, and one millisecond later the interrupt handler increments the counter, should we use a ‘greater than or equal’ comparison our timer will expire immediately (well, in 1ms…). Also, if we set it 1ms after the interrupt took place it will expire in 1,999s instead of 1s. In a scenario where increment and comparison are not asynchronous, we can avoid jitter and use a ‘greater than or equal’ comparison.